Summary - 'Attention is All You Need', AI 트랜스포머 논문 설명
Vaswani 외(2017)의 "주의력만 있으면 충분하다" -- "Attention is all you need" by Vaswani et al. (2017) -- 논문은 주의력 메커니즘에만 의존하는 기계 번역을 위한 새로운 신경망 아키텍처인 트랜스포머를 소개했습니다. 이 논문은 주의력 기반 모델이 다양한 자연어 처리 작업에서 최첨단 결과를 얻을 수 있음을 보여줌으로써 자연어 처리(NLP) 분야에 큰 변화를 가져왔습니다.

What is attention?
주의(attention)는 모델이 출력을 생성할 때 입력의 가장 관련성이 높은 부분에 집중할 수 있도록 하는 메커니즘입니다. 이는 입력의 여러 부분에 가중치를 할당하여 이루어지며, 가중치가 높을수록 중요도가 높아집니다. 그 결과 가중치가 적용된 입력의 합이 출력의 기초를 형성합니다.
How does the Transformer work?
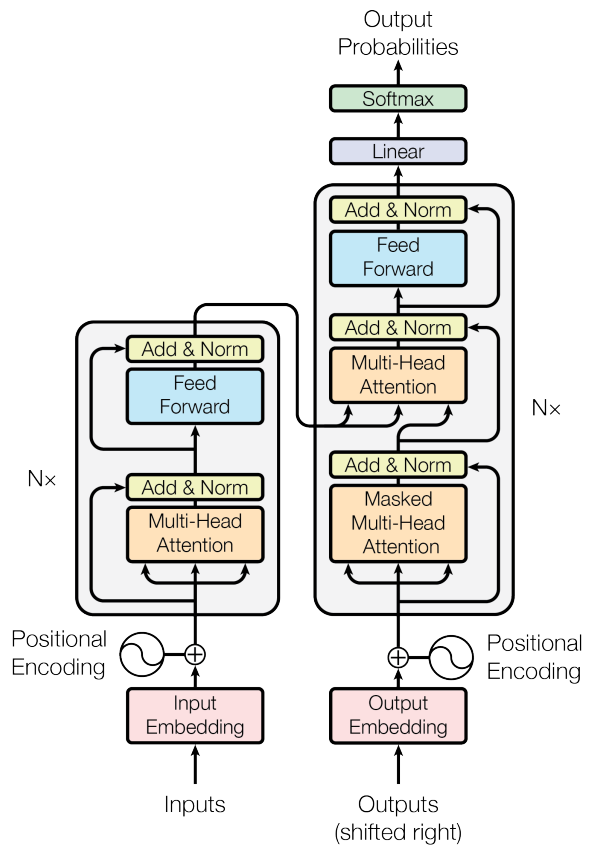
트랜스포머는 인코더-디코더 아키텍처입니다. 인코더는 입력 시퀀스(예: 한 언어로 된 문장)를 받아 입력의 표현을 생성합니다. 그런 다음 디코더는 인코더의 표현과 대상 시퀀스(예: 다른 언어로 된 해당 문장)를 가져와서 출력 시퀀스를 생성합니다.
인코더와 디코더는 모두 레이어 스택으로 구성됩니다. 각 레이어에는 두 개의 하위 레이어가 포함됩니다:
- 멀티 헤드 자체 주의 서브 레이어: 이 하위 레이어를 사용하면 모델이 입력 시퀀스의 여러 부분에 주의를 기울일 수 있습니다.
- 피드 포워드 하위 레이어입니다: 이 하위 레이어는 모델에 비선형성을 추가하는 간단한 피드 포워드 신경망입니다.
셀프 어텐션 서브 레이어는 트랜스포머의 핵심 혁신입니다. 이를 통해 모델은 입력 시퀀스에서 장거리 종속성을 학습할 수 있습니다. 이는 단거리 종속성만 학습할 수 있는 순환 신경망(RNN)과는 대조적입니다.
What are the benefits of the Transformer?
트랜스포머는 RNN에 비해 몇 가지 이점이 있습니다:
- 병렬화: 자체 주의 메커니즘을 통해 트랜스포머를 병렬화할 수 있으므로 RNN보다 훨씬 빠르게 훈련할 수 있습니다.
- 장거리 종속성: 트랜스포머는 입력 시퀀스에서 장거리 종속성을 학습할 수 있으므로 기계 번역과 같은 작업에 더 효과적입니다.
- 최첨단 결과: Transformer는 기계 번역, 텍스트 요약, 질의응답 등 다양한 NLP 작업에서 최첨단 결과를 달성했습니다.
The impact of "Attention is all you need"
"주의력만 있으면 된다"라는 논문은 NLP 분야에 큰 영향을 미쳤습니다. 이 논문은 많은 새로운 주의력 기반 모델의 개발로 이어졌고, 많은 NLP 작업의 기술 수준을 크게 향상시켰습니다.
다음은 이 논문에 대한 몇 가지 추가 세부 정보입니다:
- 이 논문은 2017년 제31회 신경 정보 처리 시스템 국제 컨퍼런스(NIPS) 논문집에 게재되었습니다.
- 이 논문은 100,000회 이상 인용되었습니다(2023년 10월 기준).
- 이 논문의 저자는 Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin입니다.
"The Attention Revolution: How 'Attention is All You Need' Transforms Machine Learning Landscape"
Vaswani 외(2017)의 논문 '주의력만 있으면 된다'는 자연어 처리(NLP) 분야에 혁신을 일으킨 트랜스포머라는 새로운 신경망 아키텍처를 소개했습니다. 트랜스포머는 주의 메커니즘에만 기반을 두고 있으며, 이전에 NLP 작업의 주요 아키텍처였던 순환 신경망(RNN)과 컨볼루션 신경망(CNN)이 필요하지 않습니다.
논문의 주요 내용
Background:
- RNN과 CNN은 NLP 작업에 주로 사용되는 아키텍처였습니다.
- RNN은 사라지는 그라데이션과 폭발하는 그라데이션으로 인해 긴 시퀀스를 훈련하는 데 어려움을 겪습니다.
- CNN은 단어 간의 장거리 종속성을 포착하는 데 한계가 있습니다.
Attention Mechanism:
- 주의 메커니즘을 통해 모델은 출력 시퀀스를 생성할 때 입력 시퀀스의 가장 관련성이 높은 부분에 집중할 수 있습니다.
- 이는 스코어링 함수를 사용하여 입력 시퀀스에서 서로 다른 위치 간의 유사성을 계산함으로써 이루어집니다.
- 그런 다음 관심도 가중치를 사용하여 출력에 대한 각 포지션의 기여도에 가중치를 부여합니다.
Transformer Architecture:
- 트랜스포머는 인코더와 디코더로 구성됩니다.
- 인코더는 자체 주의력을 사용하여 입력 시퀀스를 처리하고 숨겨진 표현을 생성합니다.
- 디코더는 주의력을 사용하여 인코더 출력에 주의를 기울이고 출력 시퀀스를 생성합니다.
- 인코더와 디코더는 모두 다중 헤드 어텐션을 사용하여 모델이 입력 시퀀스의 각기 다른 부분에 다른 방식으로 주의를 기울일 수 있도록 합니다.
Benefits of the Transformer:
- 트랜스포머는 다양한 NLP 작업에서 최첨단 성능을 발휘할 수 있습니다.
- 트랜스포머는 병렬화가 가능하기 때문에 RNN보다 더 빠르게 훈련할 수 있습니다.
- 트랜스포머는 시, 코드, 스크립트, 음악, 이메일, 편지 등과 같은 다양한 창작 텍스트 형식의 텍스트 콘텐츠를 생성하는 데 사용할 수 있습니다.
Impact:
- 트랜스포머는 NLP 분야에 큰 영향을 미쳤습니다.
- 이는 많은 새로운 NLP 모델과 애플리케이션의 개발로 이어졌습니다.
- 트랜스포머는 여전히 활발하게 연구되고 개선되고 있습니다.
다음은 주의 집중 메커니즘과 트랜스포머 아키텍처에 대한 몇 가지 추가 정보입니다:
Self-Attention:
- 자기 주의를 기울이면 모델이 입력 시퀀스의 다른 부분에 주의를 기울여 시퀀스의 표현을 계산할 수 있습니다.
- 이는 정확한 번역을 위해 모델이 단어 간의 관계를 이해해야 하는 기계 번역과 같은 작업에 유용합니다.
Multi-Head Attention:
- 다중 머리 주의(Multi-head attention)는 모델이 입력 시퀀스의 여러 부분에 다양한 방식으로 주의를 기울일 수 있게 해줍니다.
- 이는 질문 답변과 같이 모델이 질문에 정확하게 답하기 위해 입력 시퀀스의 여러 부분에 집중해야 하는 작업에 유용합니다.
Encoder and Decoder:
- 인코더는 입력 시퀀스를 처리하고 숨겨진 표현을 생성하는 역할을 합니다.
- 디코더는 인코더 출력과 관심 가중치를 기반으로 출력 시퀀스를 생성하는 역할을 합니다.
Parallelization:
- 트랜스포머는 병렬화가 가능하기 때문에 RNN보다 더 빠르게 훈련할 수 있습니다.
- 이는 입력 시퀀스의 모든 위치에 대해 주의 메커니즘을 병렬로 계산할 수 있기 때문입니다.
Impact:
- 트랜스포머는 NLP 분야에 큰 영향을 미쳤습니다.
- GPT-3, LaMDA와 같은 많은 새로운 NLP 모델과 애플리케이션의 개발로 이어졌습니다.
- 트랜스포머는 여전히 활발히 연구되고 개선되고 있으며, 앞으로도 수년 동안 NLP 분야에 큰 영향을 미칠 것으로 보입니다.
신경망의 주의력 메커니즘에 대해 설명
주의력이란 무엇이며 주의력을 계산하는 데 사용되는 다양한 점수 함수, 자기 주의와 다중 머리 주의에 대해서 설명합니다. 중요한 점은 주의력이 새로운 요소와 기존 요소 사이의 유사성을 찾는 과정이라는 것입니다. 새 요소의 값은 기존 요소의 값에 가중치를 부여한 합계에 의해 결정됩니다. 주의도를 계산하는 데 사용할 수 있는 다양한 점수 함수가 있으며, 각 점수 함수에는 고유한 장단점이 있습니다.
Scoring Functions
Let's assume k , v and q are column vectors.
- Dot product: 이것은 가장 간단한 함수이며 학습 가능한 매개변수가 없습니다. 그러나 q와 k의 크기가 같아야 합니다.
- Scaled dot product: Dot product는 Dimensions가 커질수록 증가합니다. 이 문제를 해결하는 방법은 스케일링 계수를 도입하는 것이며, 이는 트랜스포머(Transformers)에서 제안되었습니다. 이 함수에는 학습 가능한 매개 변수도 없습니다.
- Bilinear: 이 공식에서 W는 학습 행렬(a learnt matrix)입니다. 또한 q와 k의 차원은 다를 수 있습니다.
- MLP: 이 공식에서는 쿼리와 키 벡터를 연결한 다음 선형 변환을 적용합니다.
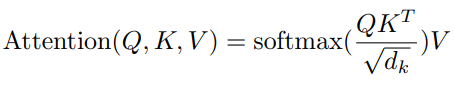
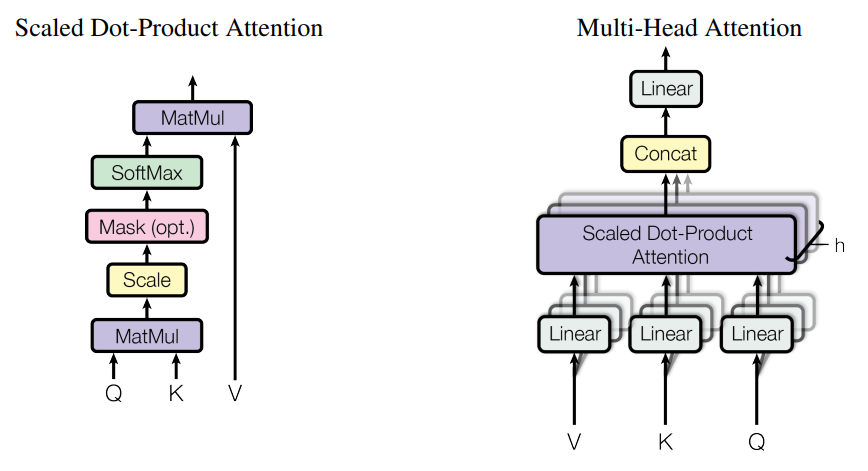
Attention & Self Attention, Multi-Head Attention
- Attention: 주의는 신경망이 입력의 여러 부분의 중요도에 가중치를 부여하는 과정입니다. 이를 통해 네트워크는 현재 진행 중인 작업과 가장 관련성이 높은 입력 부분에 집중할 수 있습니다. 주의는 다양한 작업에서 신경망의 성능을 향상시키는 데 사용할 수 있는 강력한 도구입니다.
- Self attention: 자기 주의는 네트워크가 자신의 출력에 주의를 기울이는 특별한 주의의 경우입니다. 이를 통해 네트워크는 데이터의 장거리 종속성을 학습할 수 있습니다. 자기 관심은 네트워크가 데이터의 장거리 종속성을 학습해야 하는 작업에 특히 적합한 관심의 특별한 경우입니다.
- Multi-head attention: 다중 머리 주의는 네트워크가 입력의 여러 부분에 동시에 주의를 기울일 수 있도록 하는 자기 주의의 일반화입니다. 이는 네트워크가 한 번에 여러 정보를 처리해야 하는 작업에 유용할 수 있습니다. 다중 머리 주의는 네트워크가 입력의 여러 부분에 동시에 주의를 기울일 수 있도록 하는 자기 주의의 일반화입니다. 이는 네트워크가 한 번에 여러 정보를 처리해야 하는 작업에 유용할 수 있습니다.
https://starpopomk.blogspot.com/2023/12/14-unveiling-power-of-attention-in.html
14. Unveiling the Power of Attention in Machine Learning: A Deep Dive into 'Attention is All You Need'
Discover the Rise of Machine Learning with Key Breakthroughs and Innovations. From perceptrons to SVMs, witness the evolution of machine learning.
starpopomk.blogspot.com
How deep learning differs from machine learning, 딥러닝과 머신러닝의 차이 비교
How deep learning differs from machine learning, 딥러닝과 머신러닝의 차이 비교
AI Deep Learning과 Machine Learning 차이점 비교 딥러닝과 머신러닝의 주요 차이점을 알아보세요. 머신러닝 알고리즘은 데이터(training data)에서 패턴을 추출하는 반면, 딥러닝은 신경망을 활용하여 복잡
starpopo.tistory.com
https://en.wikipedia.org/wiki/%22Attention_Is_All_You_Need%22
Attention Is All You Need - Wikipedia
From Wikipedia, the free encyclopedia 2017 research paper by Google "Attention Is All You Need" is a 2017 research paper by Google. Authored by eight scientists, it was responsible for introducing a new deep learning architecture known as the transformer.
en.wikipedia.org
'Attention Is All You Need' research paper Full text at NeurIPS Proceedings, PDF file




댓글